Q: What does "multimodal distribution" mean in computer vision literature (eg. image-to-image translation)?
While reading papers on conditional image generation using generative modeling (eg. "Toward Multimodal Image-to-Image Translation" by Zhu et al (NIPS 2017)), I wasn't clear what was meant by "one-to-many mapping" between input image domain and output image domain, "multimodal distribution" in the output image domain, or "multi-modal outputs" (eg. Quora).
Definition
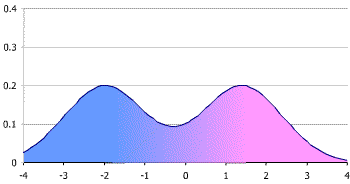
In statistics, a multimodal distribution is a continuous probability distribution with two or more modes (distinct peaks; local maxima) - wikipedia
(single-variable) bimodal distribution
bivariate multimodal distribution
In high-dimensional space (such as an Image domain: \(P(X)\) where X lives in \(d\)-dim space where \(d\) is the number of pixels, eg. \(32x32=1024\). If each pixel \(X_i\) takes a binary value (0 or 1), the size of this image domain is \(2^{1024}\). If each pixel takes an integer value \(\in [0,255]\), then the size of this image domain is \(256^{1024}\). This, by the way, is too big to compute for Mac's spotlight:
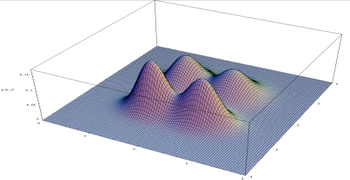
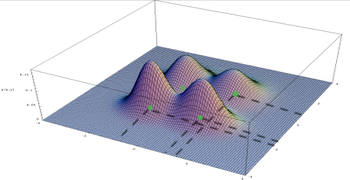
What it means by saying "the distribution of (output) image is multimodal" is to say, there are multiple images (ie. realization of the random variable (vector) X) with the (local) maxima value of the probability. In Figure below, the green dots represent the local maxima, ie. modes of the distribution. The configurations (ie. specific values/realizations) that achieves the (local) maximum probability density are the "probable/likely" images.
The green dots representing modes of the distribution over the image domain (which is abstracted into a 2Dim space for visualization, in this case)
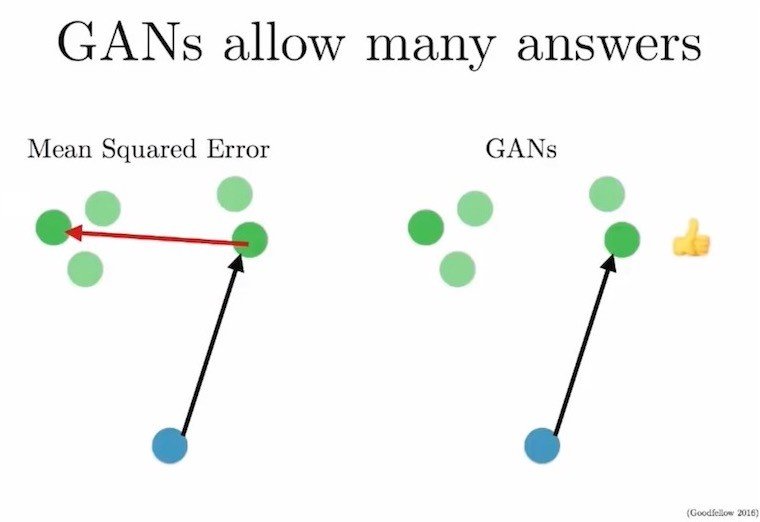
So, given one input image, if the distribution of the output image random variable is multi-modal, the standard problem of
Find \(x\) s.t. \(\underset{x \in \mathcal{X}}{\arg\max} P(X)\) (\(\mathcal{X}\) is the image space)
has multiple solutions. According to the paper (Toward Multimodal Image-to-Image Translation), many previous works have produced a "single" output image as "the" argmax of the output image distribution. But this is not accurate if the output image distribution is multi-modal. We would like to see/generate as many of those argmax configurations/output images. One way to do so, is by sampling from the output image distribution. This is the paper's approach.
Multimodal distribution as the distribution over the space of target domains [Domain adaption/transfer leraning]
So far, I viewed the multimodal distribution as a distribution over a specific domain (eg. Image domain), and the random variable corresponded to a realization, eg. an observed/sampled/output image instance. However,
Often confusing categorization of a mathematical model:
- SE
- NB: in CS, people often use "deterministic" to mean non-randomized. This causes confusion:
> "Determinism" means non-randomized. But, "Non-determinism" does not mean "randomized".
- Determinism vs. Non-Determinism
- ...? vs. stochastic/random
- a stochastic (or random) process means,
Write it down where you can see it while reading the paper
Your purpose/goal of reading may change later. You will have a different experience then.
Is there a clear answer for this question? If not, you probably should not go on reading the paper
Warm-up (1 hr)
Think of it like going on a date with a new person. It's a new relationship, so don't try/expect to understand it in one go -- this is rude:)
Go to a quiet place for a few hours. Take your coffee with you
Start by reading the title and abstract
Goal: gain a high level overview of the paper
What are the main goals of the authors?
What are the high level results?
What is the problem the paper is solving?
Skim the paper (~15min)
Look at the figures
Jot down any keywords to look out for when reading
Goal: get a sense for the layout of the paper; get keywords to look out for
Go to introduction, especially if you feel unfamiliar with the field/paper. Okay to do it often.
Goal: get other references to fill in the gap in your understanding
Carefully step through each figure
why?: each figure contain key points of the paper. Authors spend a lot of time creating them and try to condense important information that supports their experiments/hypothesis. Pay particular attention to them.
Goal: Gain feel for what the authors think is most important; Write down what to look out for when reading the paper in detail (which will follow soon)
Take a break. Walk a bit.
First ~pass~ date (1.5hr)
Start taking high level notes. Expect new words, unfamiliar ideas. Mark those (you don't yet need to understand every single word), move on.
This is your first date with the paper. You are not going to learn all gory details about it, but you will ask good questions, understand what motivated the paper, and what it's going to be about.
Begin again with the abstract, skim through the introduction*
Diligent pass through the methods section
Goal: Draw down the overall setup
Read the results and discussion
Goal: write down the key findings and how they were determined
Take a break. Do jumping jacks. Sing a song.
Let's continue.
Revisit the figures: by now, you should be able to get into nitty gritties of the figures (having read the methods, results, and discussion section)
Goal: find more gems from the figures.
Spend about 30min ~ 1hr
Second full pass (1-2hrs)
Goal:
Focus on shoring up what you didn't understand previously,
Gain a command of the methods section
Test if you can write a pseudocode
Being a critical reader of the discussion section
Details:
Pay particular attention to the areas you marked as being difficult to understand. This is why you read a new paper. Don't play safe. Okay to feel uncomfortable. Okay to do it the following day (but don't push it back too much).
Leave no word undefined, unclear. Make sure you understand every sentence.
Skim through areas you feel confident in (eg. abstract, intro, results)
What previous research and ideas were cited that this paper is building off of? (usually introduction)
Was there reasoning for performing this research, if so what was it? (introduction)
Clearly list out the objectives of the study
Did you write down 3 on your note?
Was any equipment/software used? (methods)
What variables were measured during experimentation? (methods)
Were any statistical tests used? What were their results? (methods/results)
What are the main findings? (results)
How do these results fit into the context of other research and their 'field'? (discussion)
Explain each figure and discuss their significance.
Did you write down 9 on your note?
Can the results be reproduced and is there any code available?
Name the authors, year, and title of the paper!
Are any of the authors familiar, do you know their previous work?
What key terms and concepts do I not know and need to look up in a dictionary, textbook, or ask someone?
What are your thoughts on the results? Do they seem valid?
Apply the technique
Most importantly, apply this guideline to your reading.
Modify it to suit your personality.
Write a reading report
This is the end product of your reading. Without it, you didn't do your job.
^Really.
To check out
## check out:
- Jason Eisner (JHU): [how to read a paper](https://www.cs.jhu.edu/~jason/advice/how-to-read-a-paper.html)
- Prof.Murat at Buffalo:
- [how to lead a reading group](https://tinyurl.com/rbree4d)
- [how he reads a paper](http://muratbuffalo.blogspot.com/2013/07/how-i-read-research-paper.html)
- how Prof. Nancy Lynch works: cool!
- Cathy Wu, MIT: [how to lead a reading group](https://tinyurl.com/rbree4d)
make html: generates output html files from files in content folder using
development config file
make regenerate: do make html with "listening" to new changes
vs. make publish: similar to make html except it uses settings in pulishconf.py
make serve: (re)starts a http server in the output folder. Default port is 8000
Go to localhost:<PORT> to see the output website
ghp-import -b <local-gh-branch> <outputdir>: imports content in
Workflow
Key points:
Do every work in dev branch.
Do not touch blog-build or master.
blog-build will be indirectly modified by ghp-import (or make publish-to-github)
and master is the branch that Github will access to show my website.
So, manage the source (and outputs) only in dev branch.
Local dev
Activate the right conda env with pelican library
condaactivatemy-blogcd~/Workspace/Blog
Make sure you are on dev branch
git checkout dev
(this step is for github syncing) Add new files under content
git add my-article.md
Generate the content with pelican
make html # or, make regenerate
Start a local server
make server
Open a browser and go to localhost:8000
Or whatever the port number is, set in Makefile (under the variable name of PORT)
Global dev
Use make publish instead of make html
Update the blog-build branch with contents in output folder
Push the blog-build branch's content to origin/master
These three steps can be done in one line:
makepublish-to-github
Version control the source
Important: Write new contents only on the dev branch
gitadd<files># make sure not to push the output folder
gitcm"<commit message>"
gitpushorigindev#origin/dev is the remote branch that keeps track of blog sources