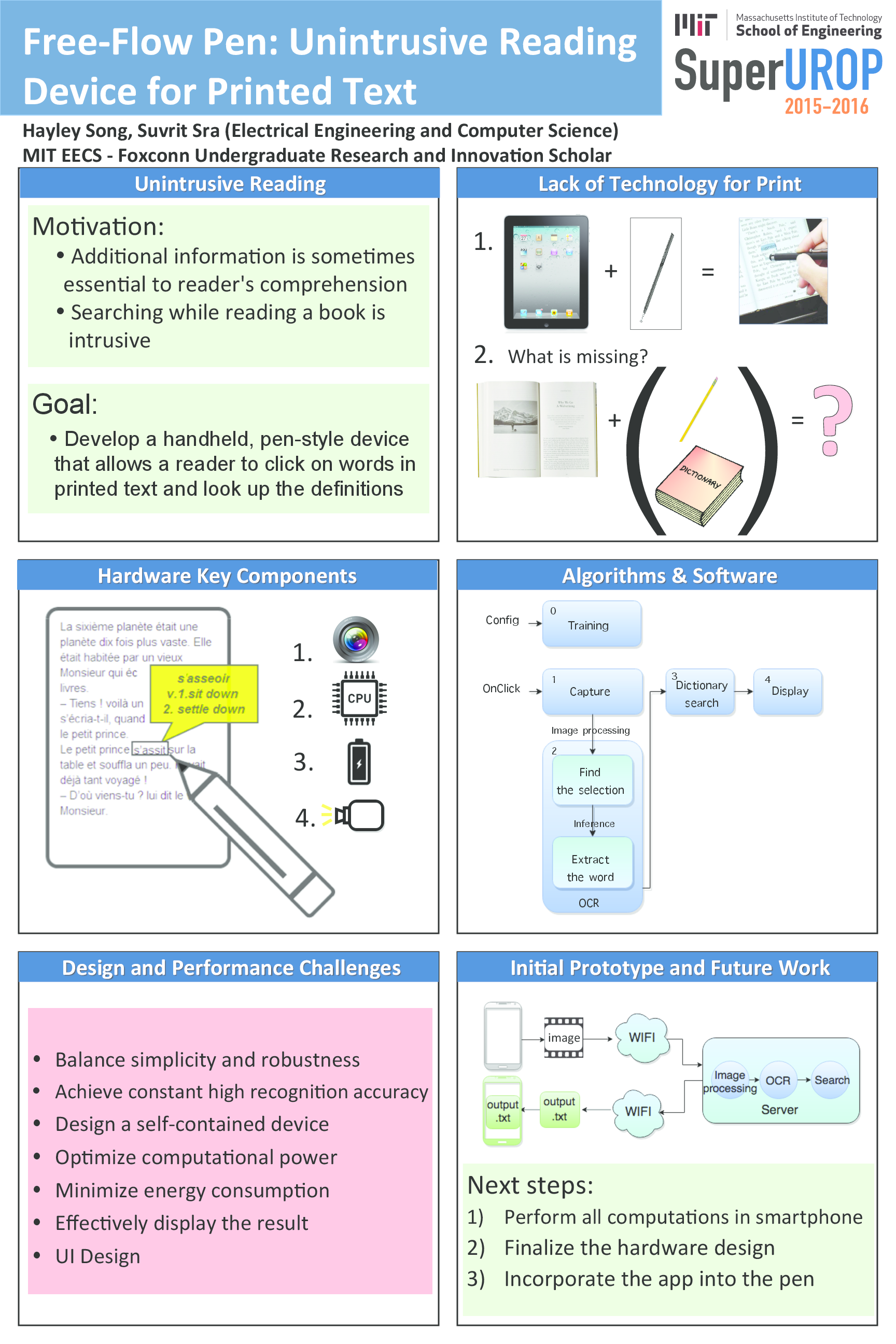
{kind=link}
FreeFlow is a software for the pen-style, hand-held device that allows a user to search for definitions by “clicking” on the printed text. It is the first end-to-end system that performs such functions with high accuracy (95%) under variable illumination and motion blur from hand movements. It is composed of the four main modules: (1) capture, (2) preprocessing, (3) recogtnition and (4) dictionary search. In this paper, we discuss the details of our system and its performances under various real-world settings.
Publications
H.Song, M.Khayatkhoei, W.AbdAlmageed. ManiFPT: Defining and Analyzing Fingerprints of Generative Models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2024. ArXiv: 2402.10401. (Project page)
H.Song, M.Khayatkhoei, W.AbdAlmageed. Formal Definition of Fingerprints Improves Attribution of Generative Models. NeurIPS Workshop on Attributing Model Behavior at Scale. 2023. OpenReview.
H.Song, P.Krawczuk, P.H.Huang. Application of Disentanglement to Map Registration Problem. arXiv preprint. 2024. ArXiv: 2408.14152.
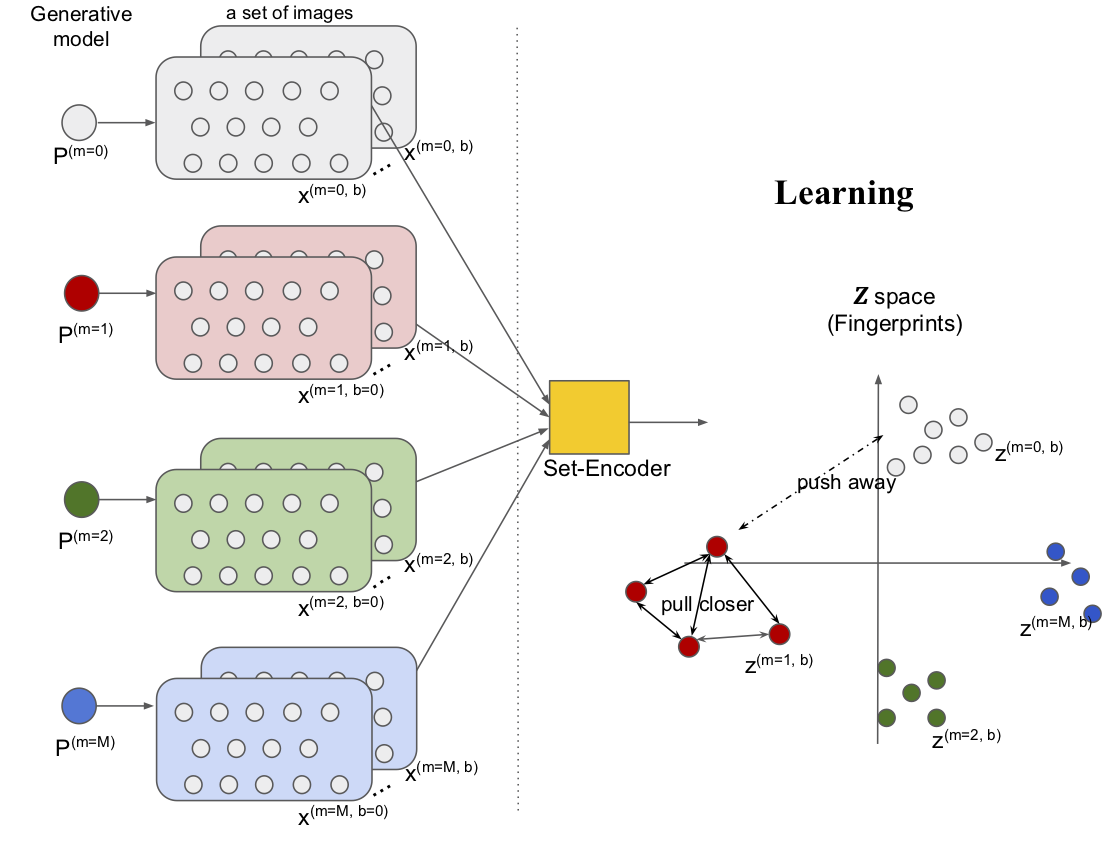
H.Song, W.AbdAlmageed. Learning Robust Representations of Generative Models Using Set-Based Artificial Fingerprints. arXiv preprint. 2022. ArXiv: 2206.02067.
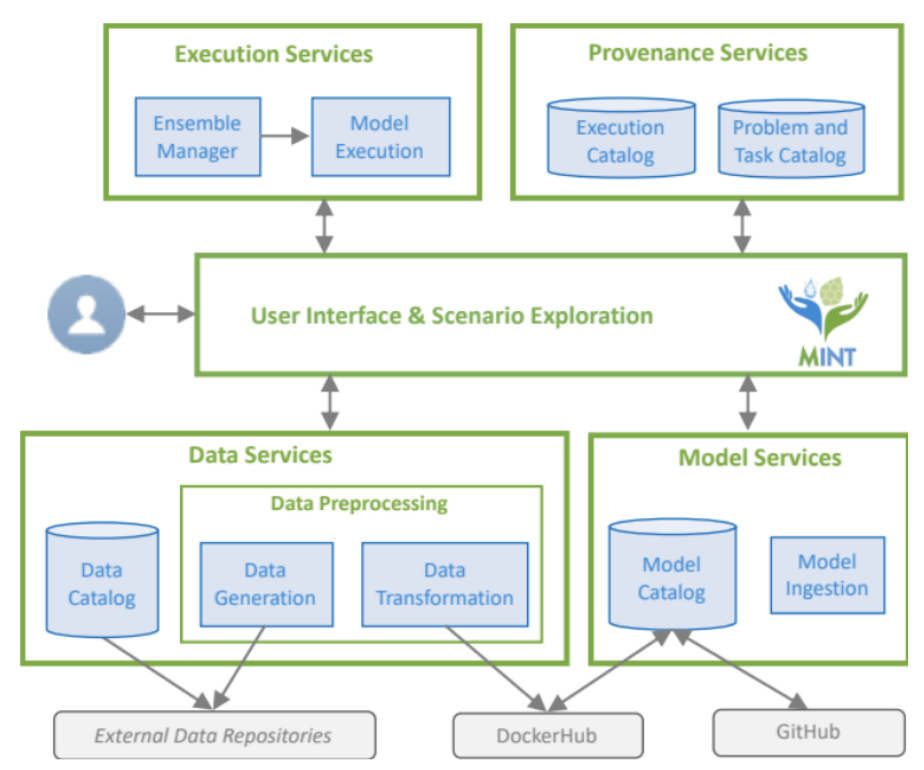
Y.Gil et al. Artificial intelligence for modeling complex systems: taming the complexity of expert models to improve decision making. ACM Transactions on Interactive Intelligent Systems. 2021. DOI: 10.1145/3453172.
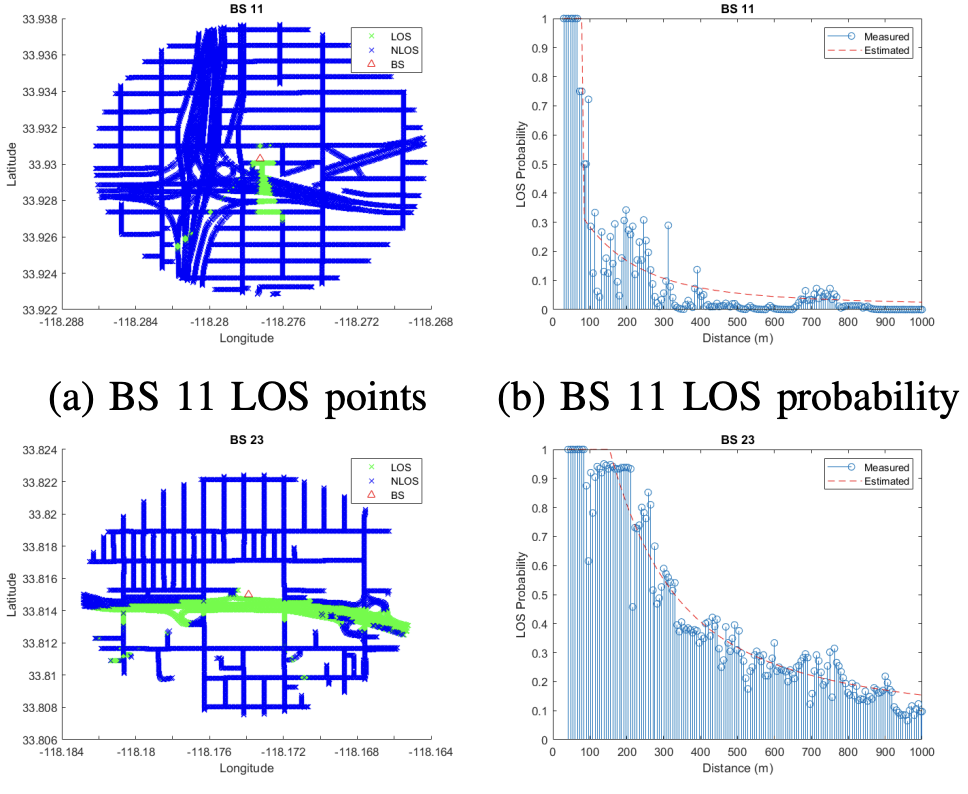
B.Modad, X.Yu, H.Song Y.Chiang, A.Molisch. Cell-by-Cell Line-of-Sight Probability Models Based on Real-World Base Station Deployment. IEEE Global Communications Conference (GLOBECOM). 2022. IEEE: 10001179.
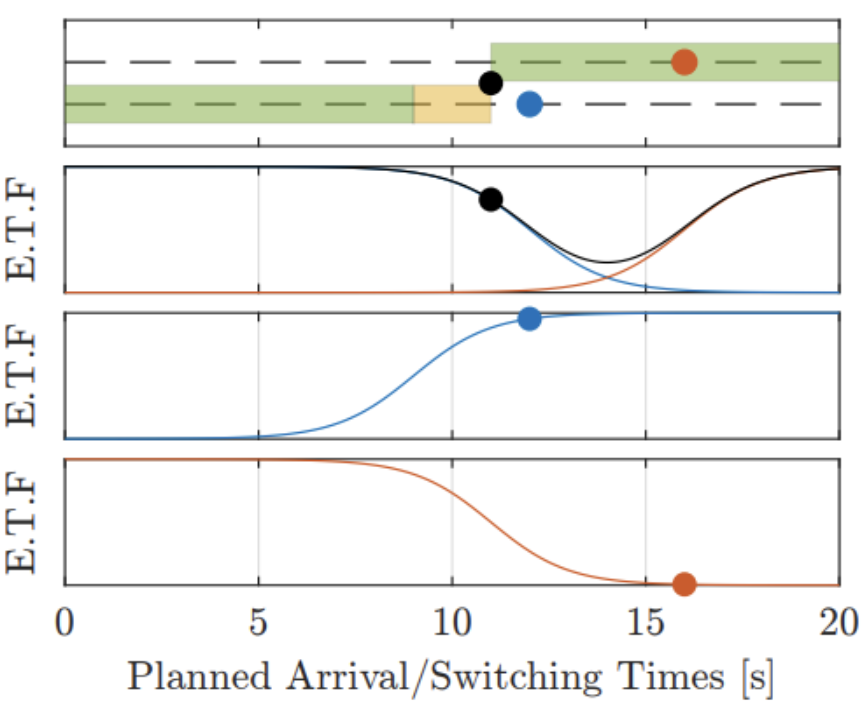
M.Rodriguez, X.Zhao, H.Song, A.Mavrommati, R.G.Valenti, A.Rajhans, P.J.Mosterman, Y.Diaz-Mercado, and H.Fathy. A gradient-based approach for coordinating smart vehicles and traffic lights at intersections. IEEE Control Systems Letters (2020), 5(6), pp.2144-2149. IEEE: 9306786
Master's Thesis

H.Song, Non-rigid registration of mammogram images using Large Displacement Optical Flow with extended flexibility for manual interventions. Thesis: M. Eng., Massachusetts Institute of Technology, Department of Electrical Engineering and Computer Science, 2018. URI.
- This thesis presents a registration method for mammogram images with extended flexibility for manual inputs from medical specialists. The algorithm was developed as part of the Mammography project led by Professor. Regina Barzilay at MIT CSAIL. Given a sequence of mammogram images, the algorithm finds an optimal registration by considering both the global and local constraints as well as user-defined constraints such as manually selected matching points. This allows the registration process to be guided by both the algorithm itself and human experts. The second half of the thesis focuses on evaluating well-known optical flow and medical registration algorithms on mammogram images. It provides insights into how they perform when encountered by challenges and constraints that are unique in mammogram images.
Papers In Progress
Learning to align the dynamics of latent sampling of GAN to the geometry of its data manifold
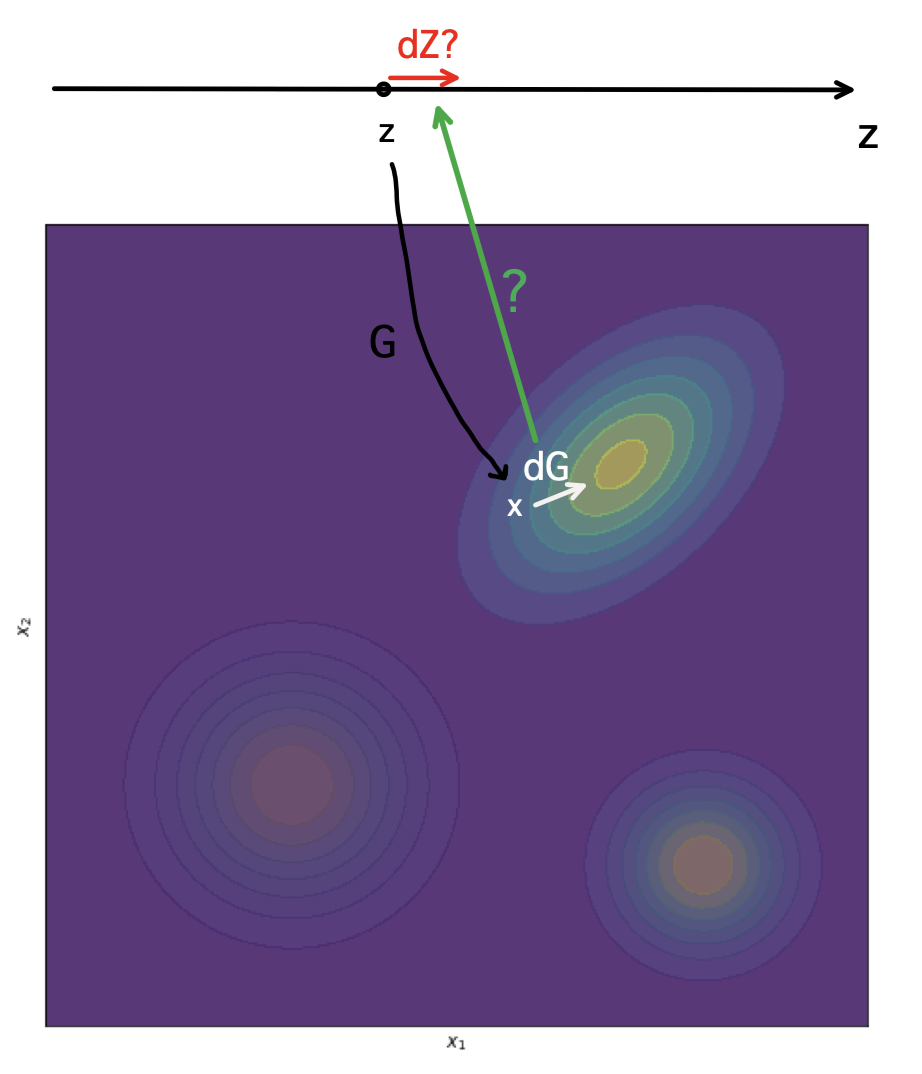
- Abstract: We develop a latent sampling method for GAN whose mixing dynamics on its latent space is guided by the geometry of the model’s data mani- fold. The generator in GAN is trained to model the true, unknown data distribution by transforming a continuous unimodal noise variable z from a standard Guassian via a neural network. To our surprise, despite this continuous transformation of continuous, unimodal input variable, GANs can fit complex, multi-modal true distribution well. This success suggests that GAN’s data-generating distribution often consists of multiple modes, each of which tries to cover points from a disconnected submanifold of the true data manifold. Given the nature of disconnected submaniofld of GAN, our project aims to find a latent sampling method that generate data points in a controlled manner so that we can collect samples from a single, chosen mode, or jump to a different mode to explore a different submanifold. In particular, we want to approach this problem from the perspectives of sampling based on dynamics, and explore a possibility of learning the dynamics on the latent space using information on the geometry of the model’s data manifold as guidance. We will explore ideas from the pull-back geometry (Arvanitidis et al. (2021a)) and recent sampling methods based on dynamics and gradient information such as Welling & Teh (2011), Girolami & Calderhead (2011), Steeg & Galstyan (2021) and Nijkamp et al. (2022). For experiments, we will start with a flow-based model, as it provides a distribution that is both explicit and invertible. Based on our findings on flows, we will expand our experiments to GANs. We will test on a synthetic dataset constructed from a mixture of five Gaussians as well as more complex datasets, MNIST, CelebA and ImageNet
BiVAE: Learning to decouple and disentangle multimodal data using bi-partitioned VAE and adversarial learning
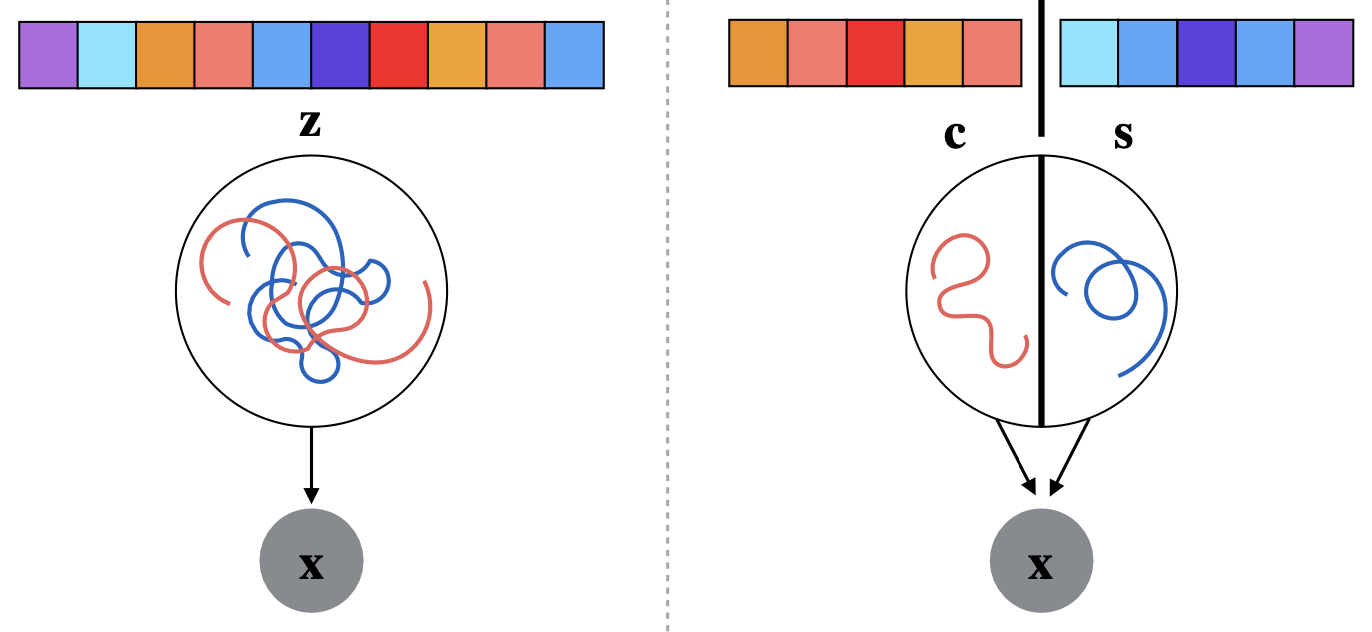
- Abstract: We consider the problem of encoding semantic information (“content”) and domain-specific information (“style”) separately from multimodal data in an unsupervised or semi-supervised setting. Unlike many existing work that learns representations strongly tied to particular supervised tasks, we aim to learn in an unsupervised or weakly-supervised way so that the representations are not tailored for any specific task, e.g. classification of the target variable, and are more representative of the data itself. We formulate this problem as the problem of learning a representation with a bi-partitioned latent space, one for the semantic information shared across the modalities and the other for the domain-specific information. Tosolve this problem, we propose the bi-latent VAE (BiVAE), a generative model that discoversand encodes the two types of information separately into proper latent partitions, with the guidance of an adversary that encourages the style to be contained exclusively in its partitionand the content partition to be agnostic of any domain-specific information. We evaluate our method on benchmark datasets and a data set of multi-source map tiles that we curated for this purpose. Our experiments on datasets from various domains show that (i) BiVAE effectively learns to capture the semantics and domain-specifics into two separate latent partitions, (ii) is capable of generating new data with controls over two orthogonal axes (semantics and styles),and (iii) enables content-based information retrieval from a multi-source dataset. In addition to our model, we introduce our new dataset, Overhead ImageNet, that serves as a new testbed for(but not limited to) the content-style disentanglement task. This dataset contains map tiles around the world collected from 5 sources such as satellites and OpenStreetMap.
Context-aware segmentation via external knowledge and structured neural net
- Abstract: Image segmentation in satellite images is a crucial task in computer vision, with important applications ranging from climate change monitoring, natural disaster responses, route planning, urban planning to security surveillance. Current state-of-the-art algorithms, including deep learning algorithms, have mostly focused on learning meaningful features exclusively from the given images. This results in neglecting a large amount of external information that provides important contexts and spatial cues that could help improve the visual tasks. In this paper, we propose a new method to achieve a spatial knowledge-aware road detection that improves existing image segmentation algorithms by utilizing spatial semantics from an external knowledge base (ie. the OpenStreetMap database). Our main contribution is first to introduce a notion of spatial semantic score that quantifies the spatial relationship and secondly to propose a new optimization framework to improve the initial prediction to better align with the spatial semantics observed in external knowledge bases. Finally, we show that our approach significantly increases performances measured by IoU, (Relaxed) F1 and Average Path Length Score (APLS) on our satellite dataset.
Reports
Generating Gaussian, Pictures, and Stories with Generative Adversarial Networks
Hayley Song*, Adam Yala*
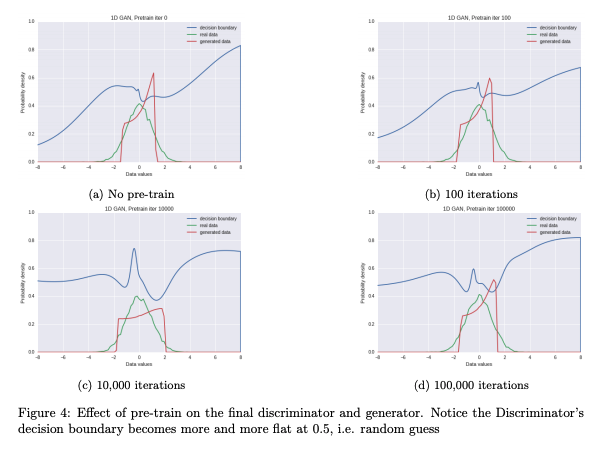
In this paper, we explore the framework of Adversarial Training as introduced in the original paper by Goodfellow et al.. Generative Aversarial Network (GAN) is a semi-supervised training method and has shown promising results in various tasks such as Image Generation, Transfer Learning, Imitation Learning and Text Generation. We aim to expose the issues and suceesses of GANs while experimenting through diverse generation tasks. Specifically, we work through generating a Gaussian distribution, images, and texts. For each experiement, we investigate the effects of parameters (e.g pre-training of the discriminator) on the convergence and the performance of the adversarial nets.
 |
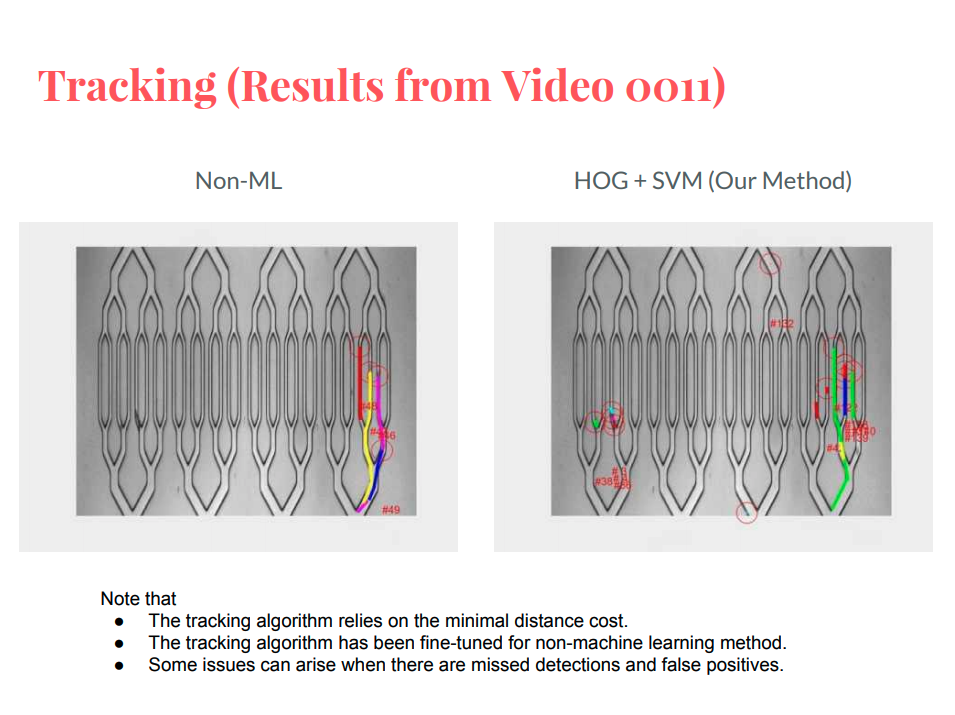
Automatic Cell Detection using HOG features and SVM
Nicha Apichitsopa*, Boying Meng*, Hayley Song*
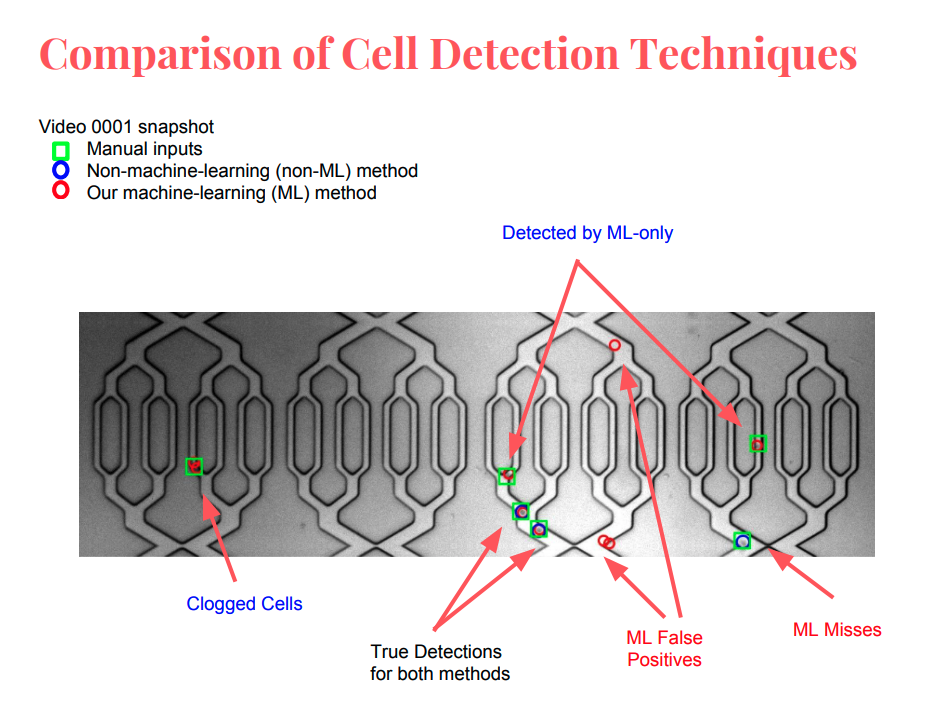
The analysis of cell trajectories inside microchannels is a critical part of many microfluidic systems. This task requires automated cell detection and cell tracking algorithms in order to reliably extract cell positions over time. Such algorithms need be robust against shape deformation, variable illumination, and noises from sensors and cell movements. In this report, we prove the ability of our machine-learning detection algorithm based on the Histogram of Oriented Gradients (HOG) and Support Vector Machines (SVMs), and compare its performances to the classic image segmentation method. We also investiage different features extracted by various machine learning algorithms and discuss how they affect the performances of cell detection and tracking.
 |
 |
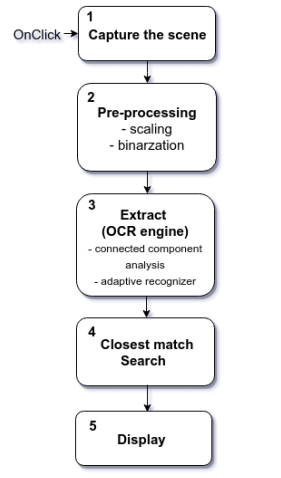
FreeFlow: Unintrusive Reading Device for Printed Texts
Hayley Song, Suvrit Sra
paper, poster (2016 Spring; MIT SuperUROP sponsored project)

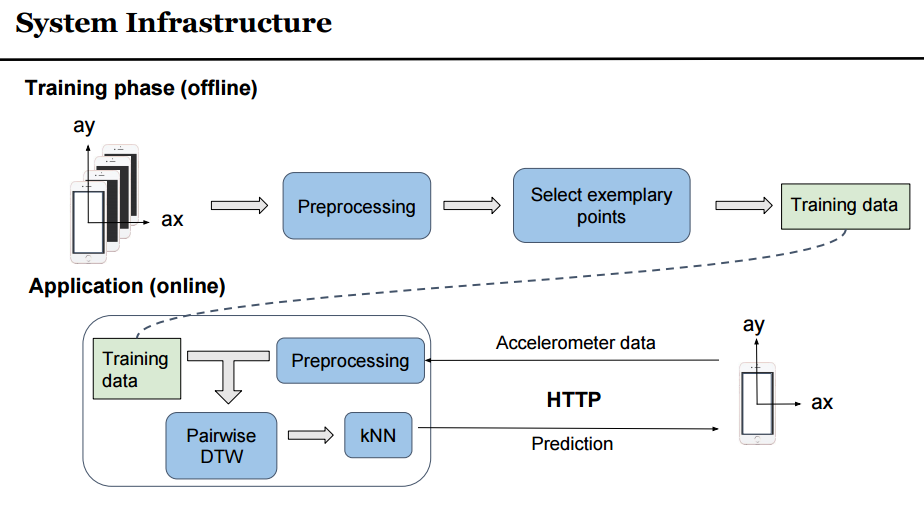
3D Air Gesture Recognizer using Dynamic Time Warping and KNN
Hayley Song*, Chongyuan Xiang*
poster, code and dataset (MIT CSAIL, 2016)
In this project, we use the Dynamic Time Warping method and the Neearest Neighbor to design a recognizer for 3D alphabet gestures drawn in the air. We collected the air gesture data from 11 users, and designed the features using speed, acceleration and rotation in the three dimensional space.
(*: Equal contribution)