Measure
 - Intuition: roughly a measure is an integral as a function of its region
- Intuition: roughly a measure is an integral as a function of its region
$$ \mu(A) = \int_{A} dx ~~\text{or,} ~~~\mu(A) = \int_{A} p(x) dx $$
For example, in geometric case, \(\mu(A)\) can be interpreted as a (physical) length (if \(A\) is one dimensional), mass (if \(A\) is two dimensional), or volumn (if three-dim) of a region \(A\). In the case that \(\mu\) is a measure of probability, \(\mu(A)\) is the probability mass of event, "random variable \(X\) takes values in the set \(A\) (also called event \(A\))"
Density
 A (probability) density is a function that transforms one measure to another measure by pointwise reweighting (on the abstract sample space \(\Omega\))
A (probability) density is a function that transforms one measure to another measure by pointwise reweighting (on the abstract sample space \(\Omega\))


- abstract probability space vs. observation space
Think of the abstract probability space as the entire system of the universe. A point in the space is a state of the universe (eg. a long vector of values assigned to all existing atoms' states). We often don't have a direct access to this "state", ie. it is not fully observable to us. Instead we observe/measure variables that are some functions of this atomic configuration/state (\(w\)). This mapping from a state of the universe to a value that the variable of our interest is observed/measured to take is called a "Random Variable".
Random Variable
 - is a function that maps a outcome in the abstract probability space's sample space \(\Lambda\) to the sample space of the observation space \(\Omega\) (often \(\mathbb{R}\))
- it is the key component that connects the abstract probability space (which we don't get to directly observe) to the observation space
- Image measure \(\mu_{X}\) is the (derived/induced) measure on the observation space that is related to the abstract probability space via the random variable \(X\).
- We need it since the measure on the abstract probability space \(\mathbb{P}\) is not known explicitly, but we need to have a way to descirbe the measure of sets in the Borel set of the observation space.
- To assign measures to an event in the observation space, we use "Image measure" \(\mu_{X}\) which is linked to \(\mathbb{P}\) via:
- is a function that maps a outcome in the abstract probability space's sample space \(\Lambda\) to the sample space of the observation space \(\Omega\) (often \(\mathbb{R}\))
- it is the key component that connects the abstract probability space (which we don't get to directly observe) to the observation space
- Image measure \(\mu_{X}\) is the (derived/induced) measure on the observation space that is related to the abstract probability space via the random variable \(X\).
- We need it since the measure on the abstract probability space \(\mathbb{P}\) is not known explicitly, but we need to have a way to descirbe the measure of sets in the Borel set of the observation space.
- To assign measures to an event in the observation space, we use "Image measure" \(\mu_{X}\) which is linked to \(\mathbb{P}\) via:
$$ \mu_{X}(A) := \mathbb{P}(X^{-1}(A))$$
- In other words, we compute the probability measure of an event \(A\) (ie.the probability that the random variable X takes a value in the set A) by:
1. Map the set A in the observation space to a space in the abstract probability space, \(A^{\leftarrow} = X^{-1}(A)\)
2. Compute the probability of event \(A^{\leftarrow}\) using \(\mathbb{P}\)
Relationship between two random variables and their image measures
"Density" describes the relationship between two random variables and their image measures:
Source
- Theoretical Foundations of Nonparametric Bayesian Models, by P.Orbanz. MLSS2009: video part 1, 2. Slides 1, 2 Great introduction of measure theory just as much in detail to be relevant for statistics (and nonparametric Bayesian models)
More resources
- MLSS09 all lecture and slide links: here
Explaining physical phenomenon consistent with observations
Bayesian data analysis is a way to iteratively building a mathemtical description of a physical phenomenon of interest using observed data.
Setup
Bayesian inference is a method of statistical inference in which Bayes' Theorem is used to update the probability for a hypothesis (\(\theta\)) as more evidence or information becomes available [wikipedia].
Therefore, it is used in the following scenario. I'll refer to the workflow as the workflow of "Bayesian data analysis" following Gelman.
-
We have some physical phenomenon (aka. process) of interest that we want to describe with mathematical language. Why? because once we have the description (aka. mathematical model of the physical phenomenon), we can use it to explain how the phenomenon works as a function of its inner components, predict how it would behave as the inner components or its input variables take different values, (... any other usage of the mathematical model?)
-
We decide how to describe the phenomenon using a mathematical language by specifying:
- Variables
- Relations
This is the step of "choosing a model family (aka. a statistical model)"
-
Now we have specified a family of probability models, each of which corresponds to a particular hypothesis/explanation of the physical process of interest. What we need to do is, to choose the "best" hypothesis from all of these possible hypotheses. To do so, we need to observe how the physical phenomenon manifests by collecting data of the outcomes of the phenomenon.
-
Collect data of the outcomes of the phenomenon.
-
"Learn"/"Fit" the model to the data. (aka, "estimate" the parameters (\(\theta\)) with the data). In English, this corresponds to "find a hypothesis of the phenomenon that matches the observed data "best"". To find such hypothesis \(\theta \in \Theta\), we need to define what is means to be the "best" hypothesis given the model (aka. Hypothesis space) and the observed data. We formulate this step as an optimization problem:
- choose a loss function \(L(\theta \mid \text{model}, \bar{X})\)
- Solve the optimization problem of finding argmin of the loss:
$$ \theta^{*} = \arg min ~~ L(\theta \mid \text{model}, \bar{x})$$
- Note: \(L(\theta \mid \text{model}, \bar{x}) \equiv L(\theta \mid \Theta, \bar{X})\). So we can rewrite the optimization objection as:
$$ \theta^{*} = \arg min_{\theta \in \Theta} ~~ L(\theta \mid \bar{x})$$
More specific scenario: a phenomenon with unobservable variables
Most physical phenomenon involves variables that we can't directly observe. These are called "Latent variables", and a statiscal model with such unobservable variables (in addition to observed/data variables) are called "Latent Variable Model". When we are focusing on the latent variable model, we often use \(Z\) as the latent variables and \(X\) as the data sample variable. That is, if we have \(N\) observation, the sample variable will be a vector of \(N\) data variables: \(X = {X_1, X_2, \dots , X_N }\). The general setup of Bayesian data analysis workflow above (ie. choose a model \(\rightarrow\) collect data \(\rightarrow\) fit the model to the data \(\rightarrow\) criticize the model \(\rightarrow\) repeat). We can express the bayesian data analysis workflow using these notations as follows:
(Note these notations are consistent with Blei MLSS2019.)
Inference
Generally speaking, inference (which stems from the Philosophy of Science)
Bayesian inference method
Bayesian inference is a method of statistical inference in which Bayes' Theorem is used to update the probability for a hypothesis(\(\theta\)) as more evidence or information becomes available wikipedia.
- My sketch
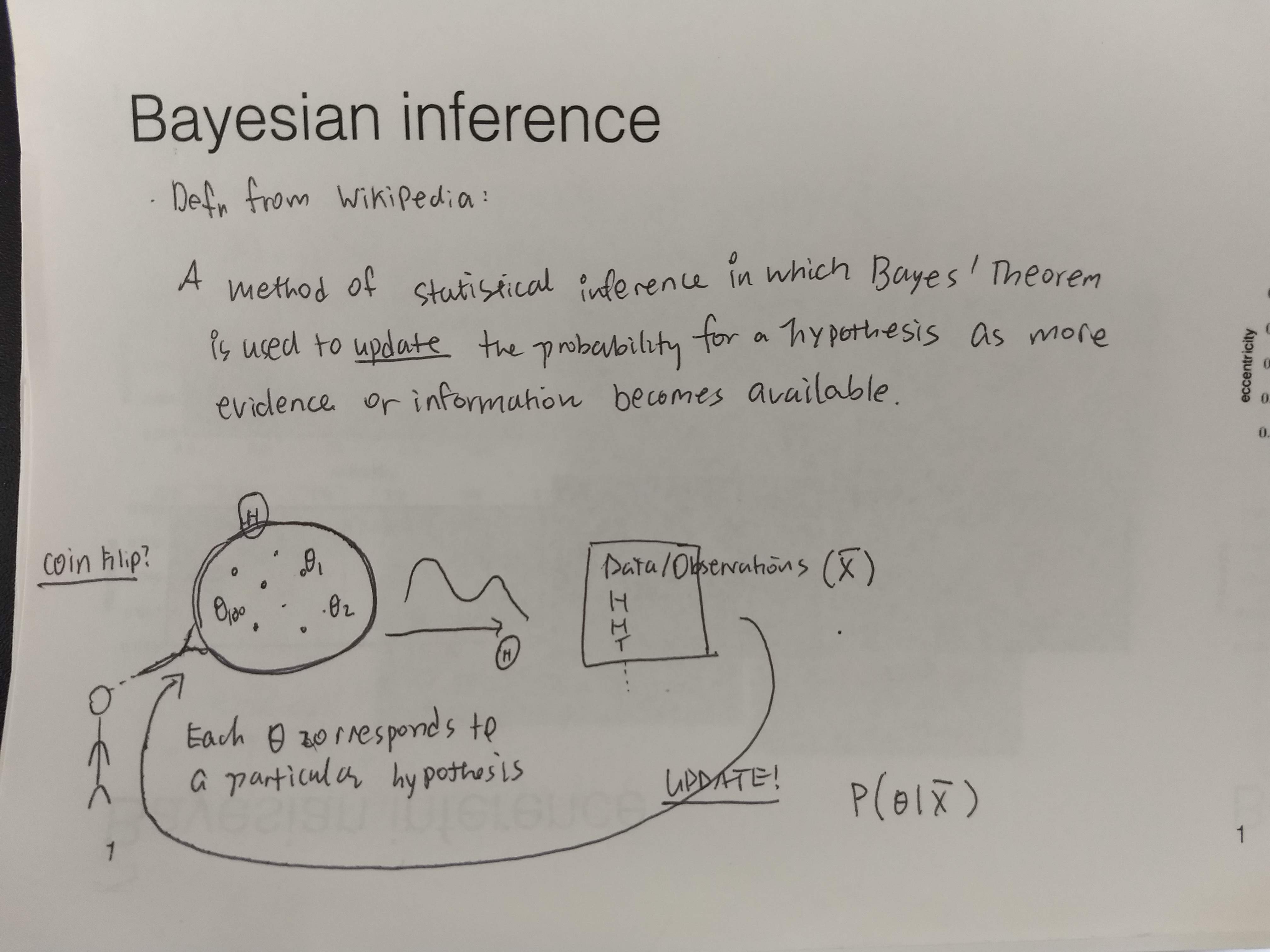
It is not a model, it is a general method(aka. technique, algorithm) that allows to infer unknowns probabilistically via computing, eg. marginal and conditional distributions of the model, the distribution over the parameters given observed data, the conditional distribution over the latent variables given the observed data.
Since it is a general technique (or an appoarch to doing inference) that is not tied to a specific model or a problem, we can use it whenever a suitable setup is presented. In the Bayesian Data analysis workflow, I see two places where we can use the Bayes theorem to infer some unknown quantities in the model (ie. use bayesian inference to compute unknowns given knowns).
-
Use bayesian inference method to learn the model from the observed data. That is, what is the probability of the parameter of the model given observation?
$$ P(\theta \mid \bar{X})$$
-
Use bayes' theorem to compute the conditional distribution of latent variables given observed data and a fixed parameter (eg. the learned parameter from step 1)
$$ P(Z \mid \bar{X}, \bar{\theta})$$
Note: I was living in the smog under the impression that "Bayesian inference" is tied to either 1 or 2. But now I understand "bayesian inference" just means computing probability distribution over the unknowns (either because they are unobservable (ie. conditional distribution of latent variables given observed data), or a subset of variables (ie. marginal distribution) that requires further computation on the joint distribution (aka. the probability model)). So, as Wikipedia's definition clarifies, anytime we have a quantity (with prior distribution) and make observations regarding a relevant process, we can update the prior distribution using the observed data via Bayes Theorem. That is all that is in the intimidating word "Bayesian inference". Gosh, can we please give another name to this way of doing computation with a probability model and data assumed to come from the probability model? "Inference" is such intimidating word. I feel like I need to do philosophy to use this word and everytime I hear this term, I feel like I never understand what the heck it is about because I don't understand what inference means in Philosophy. Yikes! :[
Approximate Inference
When we cannot compute the "flipped" probability ("flipped" using the Bayes Theorem) because it is, for example, too computationally expensive, we sometimes resort to an approximation of the true "flipped" probability.
Variational Approximate Inference
People call this "Variational Bayes", which I find it very loaded and unclear whether if the term refers to a method of inference or some model family because both "V" and "B" are captialized and it gives me an impressions that it's a name of some specific class of probability distributions. Yikes2! :[ Please give another name to it.
Variational Approximate Bayesian Inference is:
a method of finding a "good" approximate distribution to the "flipped" distribution of your probability model (ie. \(P\) with a fixed parameter \(\bar{\theta}\)) (ie2: "flipped" using Bayes theorem given your probability model) by formulating a proper optimization problem.
So far, we have discussed about "bayesian inference", and the need to sometimes be content with an "approximation" to the "flipped" distribution (given a fixed parameter and observed data). The last thing to understand is the "variational" part, which correpsonds to formulating the search for a "good" approximation distribution as an optimization problem. As usual for an optimization problem, we need to define "goodness", or in this case "loss"
- Sketch for understanding the motivation for variational bayesian inference method (aka. Variational Bayes)

To be continued...