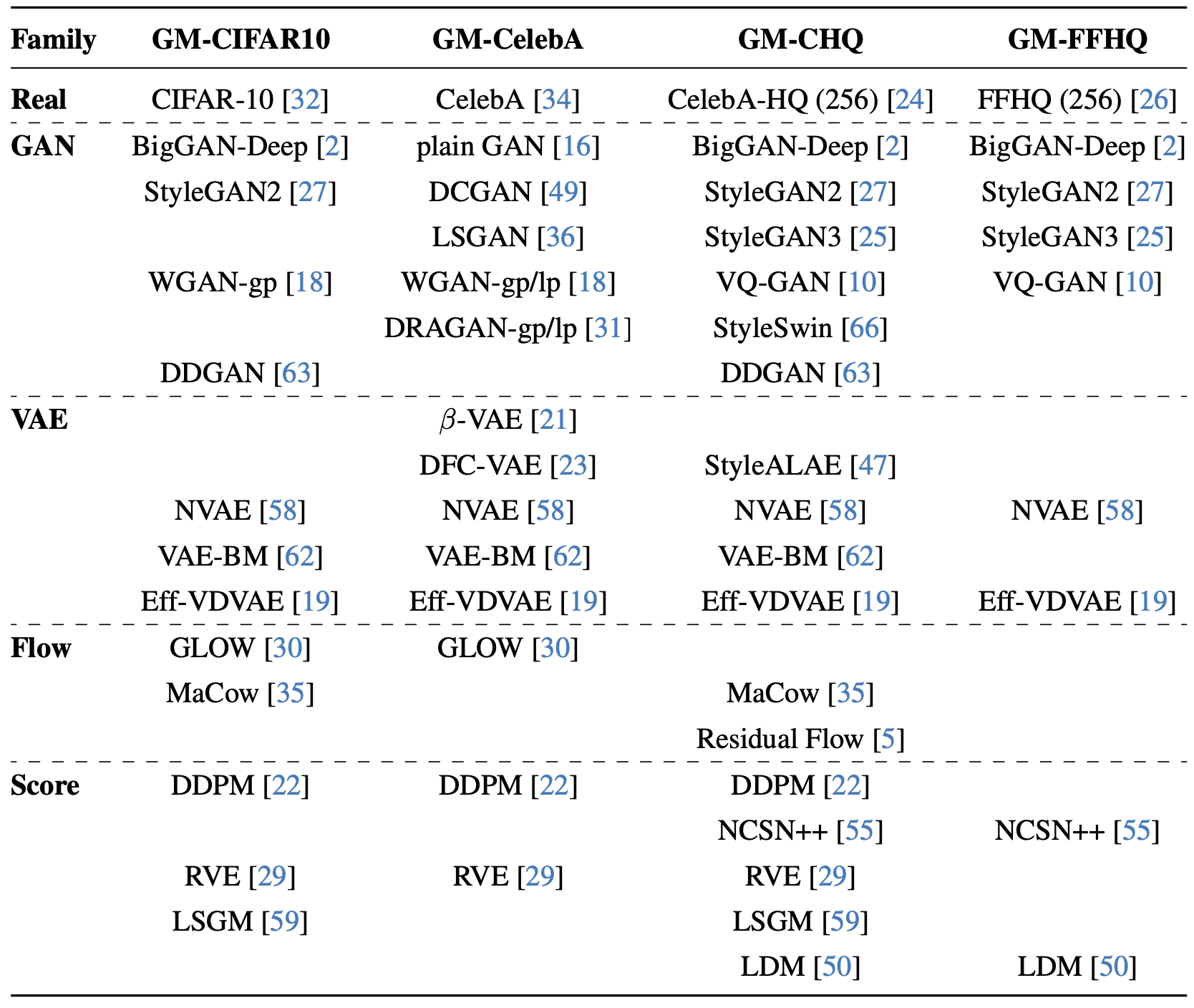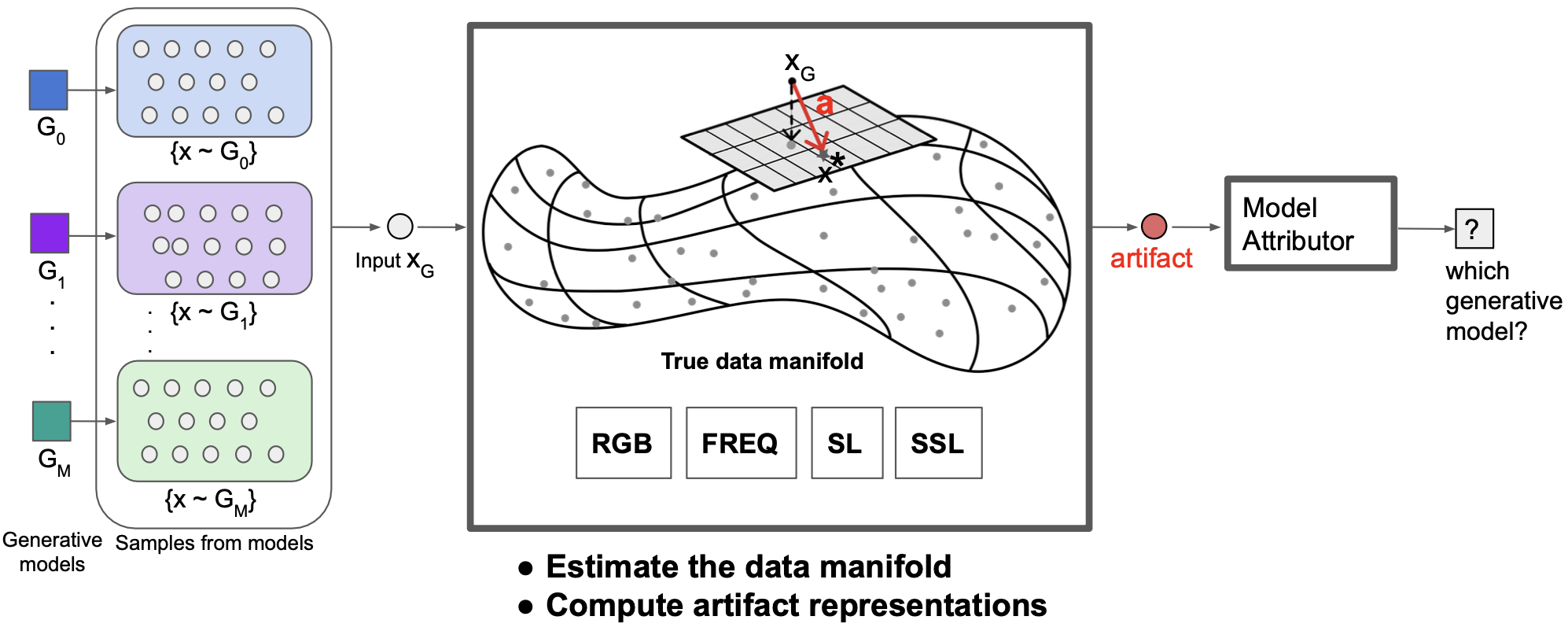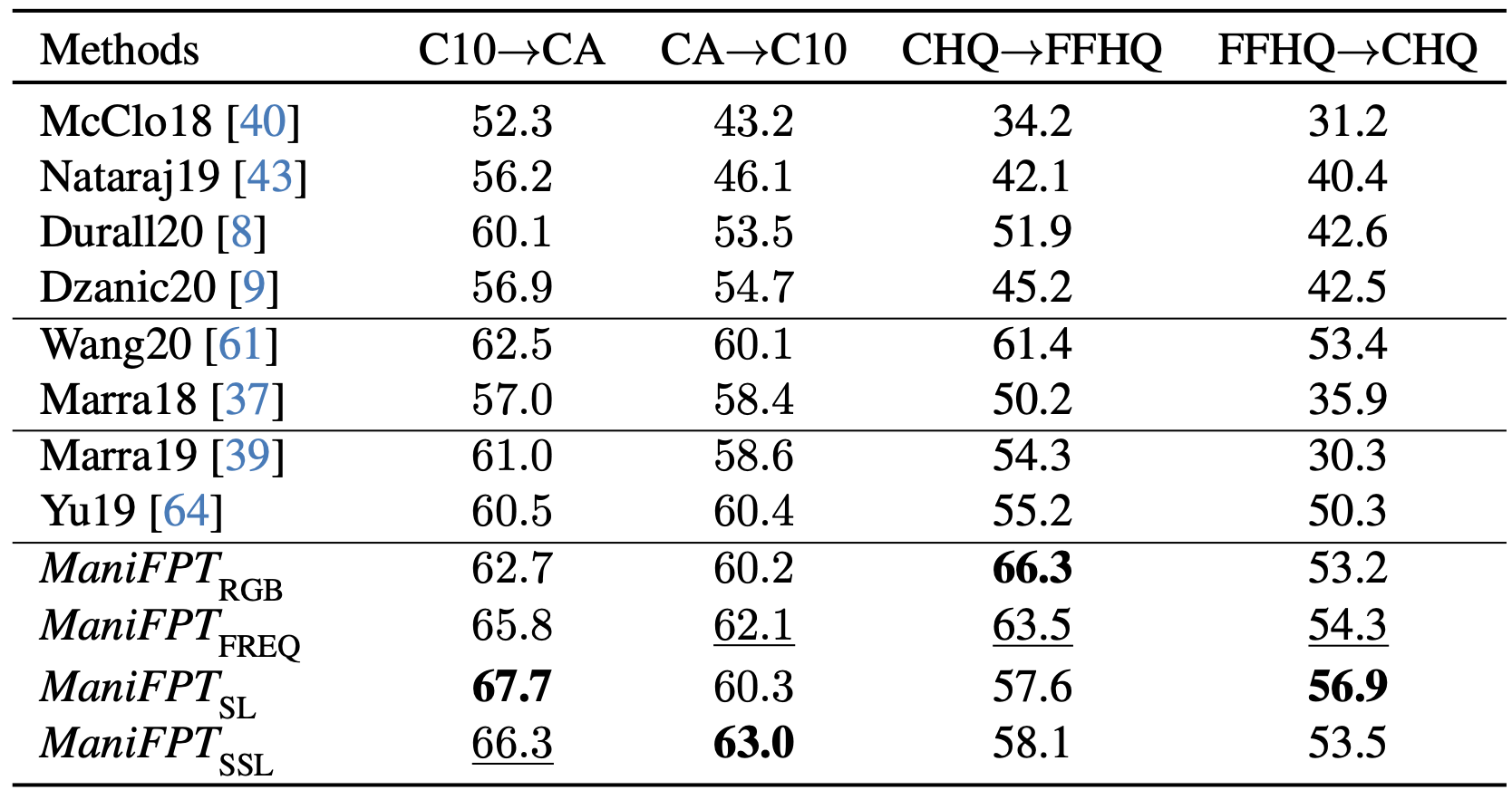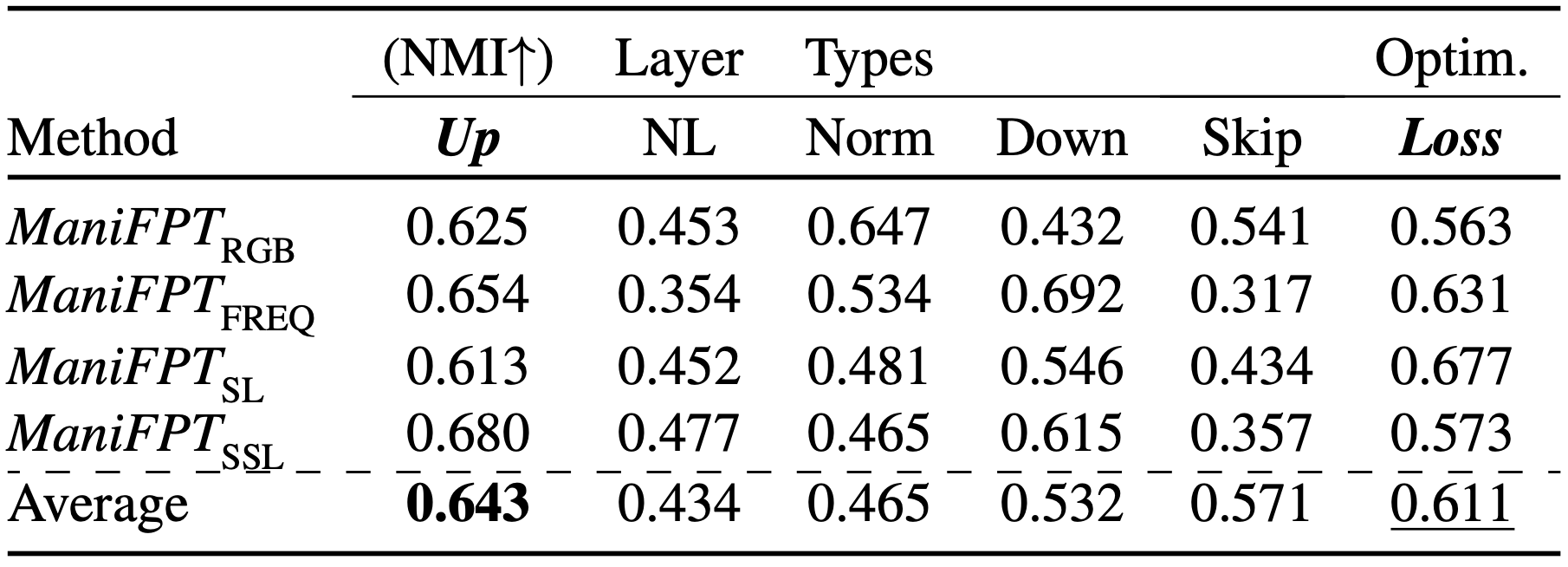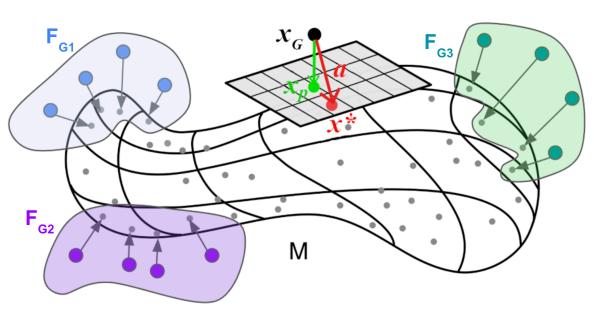
Our proposed manifold-based definition of artifacts and fingerprints of a generative model.
We estimate the true data manifold M using real samples and compute an artifact a as the difference between a gen- erated sample and its closest point in the real dataset. We define the fingerprint F of a generative model as the set of all its artifacts.
We estimate the true data manifold M using real samples and compute an artifact a as the difference between a gen- erated sample and its closest point in the real dataset. We define the fingerprint F of a generative model as the set of all its artifacts.